[Spring] Fetch Join과 Pagination을 함께 쓰면 안 되는 이유
들어가며
Spring Data JPA를 사용하다 보면 N+1 문제를 해결하기 위해 fetch join을 자주 사용한다.
또한, Pagenation(이하 페이징)을 사용하여 모든 데이터를 가져오는것이 아닌, 원하는 수량만의 데이터를 가져올 수 있다.
하지만, Fetch join과 페이징을 동시에 적용할 때는 문제가 발생할 수 있다.
이번 글에서는 Fetch join과 Pagination을 함께 사용할 때 발생하는 문제와 해결 방법을 정리해 보았다.
Fetch join과 페이징 개념 정리
Fetch join은 N+1을 해결하기 위해 자주 사용하는 방법이다.
연관 엔티티가 LAZY로 설정된 경우, 반복 접근 시 N+1 문제가 발생할 수 있다.
하지만 아래와 같은 Fetch join 코드를 사용하면 연관 데이터를 한 번에 가져와 문제를 해결할 수 있다.
게시물과 댓글을 Fetch join으로 조회
@Query("SELECT p FROM Post p LEFT JOIN FETCH p.comments")
List<Post> findAllWithComments();
하지만 데이터가 많아질 경우 모든 데이터를 한 번에 불러오는 것은 서버에 부담이 될 수 있다.
이를 위해 페이징 처리가 필요하다.
JPA에서는 Page와 Pageable을 활용하여 손쉽게 페이징 기능을 구현할 수 있다.
Fetch join + 페이징
//Repository 코드
@Query("SELECT p FROM Post p LEFT JOIN FETCH p.comments")
Page<Post> findAllWithComments(Pageable pageable);
// 사용 예시 (5개 조회)
Pageable pageable = PageRequest.of(0, 5);
Page<Post> posts = postRepository.findAllWithComments(pageable);
위 코드를 통해, 원하는 데이터를 원하는 수량만큼 한번에 조회 가능하다.
하지만 실제로 해당 동작의 쿼리 로그를 확인해보면, 결과는 정상적으로 보이지만 내부적으로는 문제가 있다는 것을 알 수 있다.
실제 쿼리 로그를 통해 그 문제를 살펴보자.
JPQL fetch join + 페이징의 실제 쿼리 로그
아래는 Fetch join과 페이징을 같이 수행한 쿼리의 로그 화면이다.
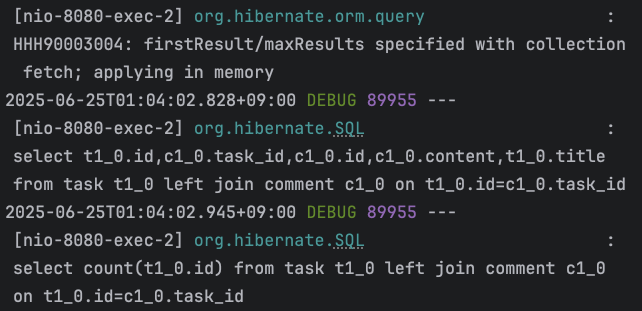
실제 쿼리 로그
select t1_0.id,c1_0.task_id,c1_0.id,c1_0.content,t1_0.title
from task t1_0
left join comment c1_0
on t1_0.id=c1_0.task_id
쿼리를 살펴보면, pageable을 사용하여 5개의 데이터 페이징을 요청했지만, 쿼리의 끝에 limit이 붙지 않는다는 것이다.
하지만 결과는 5개의 Task데이터 및, 그에 해당하는 댓글 목록만을 반환한다.
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
위 로그에서 발견되는 점이, 전체 데이터를 가져와서 메모리에서 처리했다는 메시지이다.
Fetch Join을 통해 데이터를 가져올 때, DB에서 5개의 데이터를 가져오는 것이 아닌, 모든 데이터를 가져와서 서버에서 5개만을 반환한다는 사실이다.
이는 성능 면에서 매우 큰 문제가 발생할 수 있다.
앞서 언급했듯이, 데이터가 많아질 경우 모든 데이터를 한 번에 불러오는 것은 서버에 부담이 되기 때문에 페이징 처리가 필요하다.
하지만 페이징을 적용했음에도, 실제로는 모든 데이터를 가져와서 서버 메모리에서 페이징을 처리한다는 것은 성능 문제가 해결되지 않은 것이다.
그렇다면 왜 이런 현상이 발생하는지 더 자세히 살펴보자.
JPQL에서 fetch join + 페이징의 문제점
이런 문제가 발생하는 근본적인 원인은 1:N 관계에서 페이징 처리와 페치 조인을 함께 사용할 때 발생하는 제약 때문이다.
즉, 단순히 두 기능을 조합한다고 해서 항상 안전하게 원하는 결과를 얻을 수 있는 것은 아니다.
1:N관계에서 Join의 문제점과 이 문제를 Jpa가 해결하는법을 각각 정리해보자.
Join과 페이징의 근본적 문제: 카티션 곱
이 문제의 본질은 Join과 페이징이 근본적으로 충돌하기 때문이다. 1:N 관계에서 Join을 하면, N의 개수만큼 결과가 늘어난다(카티션 곱).
예를 들어, Task 3개와 각각의 Comment가 있다고 가정해보자.
카티션 곱 예시
| Task ID | Task 제목 | Comment ID | Comment 내용 |
|---|---|---|---|
| 1 | 첫 번째 작업 | 1 | 댓글 1-1 |
| 1 | 첫 번째 작업 | 2 | 댓글 1-2 |
| 2 | 두 번째 작업 | 3 | 댓글 2-1 |
| 2 | 두 번째 작업 | 4 | 댓글 2-2 |
| 2 | 두 번째 작업 | 5 | 댓글 2-3 |
| 3 | 세 번째 작업 | 6 | 댓글 3-1 |
위 표에서 볼 수 있듯이, Task는 3개지만 Join 결과는 6개의 행이 된다.
이때 DB에서 LIMIT 3을 적용하면, Task 기준이 아닌 전체 결과 행 기준으로 제한이 걸리기 때문에,
Task를 기준으로 3개의 데이터 및 댓글 데이터가 아닌 전체 행을 기준으로 LIMIT3이 걸리는 것이다.
JPA는 이러한 문제를 피하기 위해, LIMIT을 DB에서 직접 적용하는 대신 전체 결과를 가져온 뒤 메모리에서 페이징 처리를 수행한다.
Join + 페이징의 문제점 정리
- 1:N Join 시, 결과 row가 N만큼 늘어난다
- DB에서 limit을 걸면, 하나의 Task에 대한 Comment가 중간에 잘릴 수 있다
- JPA는 Task 엔티티 기준으로 중복을 제거한 후, 요청한 페이지 크기만큼 반환한다
- 데이터가 많으면 OutOfMemory 등 심각한 문제가 발생할 수 있다.
실제 동작 코드 살펴보기
위의 방식대로 JPA가 동작하는지 실제 JPA코드를 확인해 보자.
페이징된 데이터를 반환할 때 Spring Data JPA는 SimpleJpaRepository 클래스의 findAll(…) 메서드를 사용한다.
// SimpleJpaRepository.java
@Override
public Page<T> findAll(@Nullable Specification<T> spec, @Nullable Specification<T> countSpec, Pageable pageable) {
TypedQuery<T> query = getQuery(spec, pageable);
return pageable.isUnpaged() ? new PageImpl<>(query.getResultList())
: readPage(query, getDomainClass(), pageable, countSpec);
}
여기서 readPage(…)에서 페이징 로직수행된다.
…
해결방법
앞서 살펴본 것처럼, Fetch join과 페이징을 함께 사용하면 JPA가 메모리에서 페이징을 처리하게 되어 성능상 문제가 발생한다.
따라서 Fetch join과 페이징은 함께 사용하면 안 되고, 반드시 분리해서 사용해야 한다.
아래는 몇가지 해결 방법을 정리해본 내용이다.
핵심은 데이터를 한번에 조회해 오는것이 아닌, 나누어서 조회해야한다는 점이다.
Batch fetch 사용
JPA는 @BatchSize 옵션을 제공한다. 이 옵션을 사용하면, 1차 쿼리로 Task만 페이징해서 가져오고, 2차 쿼리로 연관된 Comment를 in 쿼리로 한 번에 가져온다.
@BatchSize 사용 예시
@Entity
public class Task {
@Id @GeneratedValue
private Long id;
private String title;
@OneToMany(mappedBy = "task", fetch = FetchType.LAZY)
@BatchSize(size = 10)
private List<Comment> comments = new ArrayList<>();
}
application.yml에서 글로벌 설정도 가능하다.
<h4>글로벌 batch-size 설정</h4>
jpa:
properties:
hibernate:
default_batch_fetch_size: 10
이렇게 하면, 페이징 쿼리는 아래처럼 두 번 나간다.
//1차 쿼리: Task 페이징
select * from task order by id limit 10
//2차 쿼리: Comment in 쿼리
select * from comment where task_id in (1,2,3,...,10)
QueryDSL 사용
QueryDSL을 사용해서 작성한 코드는 아래와 같다.
QueryDSL로 쿼리 분리
public Page<TaskDto> findWithPage(Pageable pageable) {
// 1단계: Task만 페이징해서 조회
List<TaskDto> tasks = jPAQueryFactory
.select(
new QTaskDto(task.id, task.title)
)
.from(task)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 2단계: 조회된 Task들의 ID로 Comment 조회
if(!tasks.isEmpty()) {
List<Long> taskIds = tasks.stream()
.map(TaskDto::getId)
.collect(Collectors.toList());
List<CommentDto> comments = jPAQueryFactory
.select(
new QCommentDto(comment.id, comment.content, comment.task.id)
)
.from(comment)
.where(comment.task.id.in(taskIds))
.fetch();
// 3단계: Comment를 Task ID별로 그룹핑하여 매핑
Map<Long, List<CommentDto>> commentMap = comments.stream()
.collect(Collectors.groupingBy(CommentDto::getId));
tasks.forEach(task -> {
task.setComments(commentMap.getOrDefault(task.getId(), new ArrayList<>()));
});
}
// 4단계: 전체 Task 개수 조회
Long total = jPAQueryFactory
.select(task.count())
.from(task)
.fetchOne();
long totals = total != null ? total : 0L;
return new PageImpl<>(tasks, pageable, totals);
}
QueryDsl 사용 방법 역시, BatchSize와 마찬가지로 Task를 먼저 페이징하여 가져온 후, Comment 및 전체 수를 따로 조회하는 방식으로 문제를 해결한다.
두가지 방법 요약
두가지 방식 모드 Task를 먼저 페이징 하여 가져온 뒤, Comment를 가져오는 방식을 사용한다.
BatchSize 방식은 JPA의 기본 기능을 활용하는 방법으로, 엔티티에 @BatchSize 어노테이션을 추가하거나 글로벌 설정으로 간단하게 적용할 수 있다.
이 방식은 구현이 간단하고 JPA의 자동화된 기능을 그대로 활용할 수 있다는 장점이 있지만, 복잡한 조건이나 동적 쿼리에는 한계가 있다.
QueryDSL 방식은 개발자가 직접 쿼리를 작성하여 더 세밀한 제어가 가능하다. 복잡한 조건문, 동적 정렬, 서브쿼리, 집계 함수 등 다양한 쿼리 패턴을 구현할 수 있으며, QueryProjection을 통해 타입 안전성도 보장받을 수 있다. 또한 성능 최적화를 위한 배치 처리나 조건부 조회 로직을 세밀하게 조정할 수 있다.
따라서 간단한 조건이라면 BatchSize가 적절할 것이고, 복잡한 조건과 정렬 조건, 동적 쿼리가 요구되는 경우라면 QueryDSL 방식이 적절할 것이다.
결론
JPA를 사용할 때 연관관계에서 필요한 데이터를 한 번에 가져오는 것도 성능상 중요하고, 전체 데이터가 아닌 필요한 만큼 페이징해서 가져오는 것도 성능상 중요하다.
하지만 이 두 가지를 같이 쓰면 예상치 못한 문제가 발생한다.
앞선 예시에서 Fetch join과 페이징을 동시에 사용하면 결과는 원하는 결과가 나오지만, 실제로는 성능상 최악의 방법을 사용한다는 것이다.
즉, 겉보기에는 정상적으로 작동하는 것처럼 보이지만, 내부적으로는 모든 데이터를 메모리에 올려서 처리하고 있다는 것이다.
이 내용을 확인해보기 위해 1:N 관계에서 Join 결과와, 거기에 limit이 걸릴 때 문제를 확인했다.
카티션 곱으로 인해 데이터가 N배로 늘어나는 현상과, DB에서 limit을 적용하면 의도한 엔티티가 아닌 중간에 잘린 엔티티가 포함될 수 있다는 점을 알아보았다.
JPA는 이러한 문제를 피하기 위해 메모리에서 페이징을 처리하지만, 이는 오히려 더 큰 성능 문제를 발생시킨다는 점도 알아보았다.
전체 데이터를 메모리에 올려야 하므로 OutOfMemoryError 위험이 있고, 네트워크 부하도 증가하며, 데이터 증가에 따른 확장성 문제가 발생한다.
따라서 Fetch join과 페이징이 필요한 상황에서는 반드시 분리해서 사용해야 한다.
Batch fetch나 QueryDSL을 활용한 쿼리 분리 방식을 통해, 안전하고 효율적인 데이터 조회가 가능하다.
개발자로서 중요한 것은, 단순히 동작하는 코드가 아니라 왜 그렇게 동작하는지, 어떤 문제가 발생할 수 있는지를 깊이 이해하는 것이 중요하다는것을 이번 기회에 다시 깨닳았다.
앞으로도 JPA를 사용할 때는 쿼리 로그를 꼼꼼히 확인하고, 해당 쿼리가 성능상 문제가 없는지, 최적화된 쿼리인지 확인해 보는 작업이 중요하다는것을 다시 느낀다.
댓글남기기